2024 年 3 月,Nvidia 推出了 NIM(Nvidia Inference Microservices)微服务平台,旨在加速生成式 AI 模型在云端、数据中心和工作站上的部署和使用。
本文将介绍 Nvidia NIM 的核心功能、主要优势和应用领域,并为新手用户准备了一份 Nvidia NIM API 接入指南。
什么是 Nvidia NIM?
NIM(Nvidia Inference Microservices)是 Nvidia 专为生成式 AI 模型推理设计的产品,它为开发者提供了多种使用方式:
- Nvidia NIM API:以 API 形式开放调用。
- Nvidia AI Enterprise 组件:NIM 是 Nvidia AI Enterprise 平台的重要组成部分,该平台基于 VMware 和 Red Hat 的基础软件构建。
- Nvidia NIM 自托管容器:可以在工作站和配备 Nvidia GPU 的机器上本地部署。
通过这些方式,你可以灵活选择最适合自身需求的 NIM 部署方案,从而充分利用 Nvidia 的 AI 推理能力。
Nvidia NIM API 简介
Nvidia NIM API 是一套符合行业标准的 API,帮助你轻松部署 AI 模型。作为无服务器推理端点,NIM API 提供了一个安全、简便的途径,助力快速开发和迭代生成式 AI 解决方案。
NIM API 的强大基础包括 Triton Inference Server、TensorRT、TensorRT-LLM 和 PyTorch 等推理引擎。这种架构支持大规模 AI 推理,让你可以使用最先进的基础模型和微调模型,而无需操心基础设施问题。
NIM API 主要特点
- 与 OpenAI 兼容:可以使用标准 HTTP REST 客户端或 OpenAI 客户端库进行调用。
- 提供多个端点:方便与 AI 模型交互:
- 文本完成端点:根据提示词生成文本。
- 文本嵌入端点:生成输入文本的嵌入向量。
- 检索端点:根据查询检索相关文档。
- 排序端点:根据查询或提示词对段落或文档排序。
- 与 LLM 编排工具集成:支持与 LangChain 和 LlamaIndex 等工具结合,轻松构建聊天机器人、AI 助手、RAG 应用及基于智能体的高级应用。
使用 Nvidia NIM API(免费额度)
1访问 Nvidia NIM 官方网站,点击右上角的「Login」。
2输入你的电子邮件地址,然后点击「Next」。
3已经有 Nvidia 账户可以直接登录,没有就走新建流程(过程简单明了)。
4新账户会收到 1000 个免费积分,每个积分对应一次推理调用。验证企业邮箱后,积分可增加到 5000 个,方法是点击「Request More」>「Get Started」。
5点击任意一个「Chat」,依次点击「Get API Key」>「Generate Key」,生成密钥后点击「Copy Key」复制并保存好。
6使用以下地址和刚生成的密钥即可调用 Nvidia NIM API,可以「点击这里」查看所有可用模型:
https://integrate.api.nvidia.com/v1
7Nvidia NIM API 的model名称带有发布商名称,可在 One API 等接口管理和分发系统中进行模型关系映射,例如:
{
"phi-3.5-mini-instruct": "microsoft/phi-3.5-mini-instruct",
"phi-3.5-vision-instruct": "microsoft/phi-3.5-vision-instruct",
"phi-3.5-moe-instruct": "microsoft/phi-3.5-moe-instruct",
"gemma-2-2b-it": "google/gemma-2-2b-it",
"gemma-2-9b-it": "google/gemma-2-9b-it",
"gemma-2-27b-it": "google/gemma-2-27b-it",
"llama-3.1-8b-instruct": "meta/llama-3.1-8b-instruct",
"llama-3.1-70b-instruct": "meta/llama-3.1-70b-instruct",
"llama-3.1-405b-instruct": "meta/llama-3.1-405b-instruct"
}
Nvidia NIM 正迅速成为开发者首选的生成式 AI 模型平台。例如,Google 在推出 Gemma 2 2B 时,就同时在 NIM、Hugging Face 和 Kaggle 上进行发布。预计未来会有更多模型提供商会将它作为首选模型发布平台之一。
Nvidia NIM 在 Nvidia AI Enterprise 中的应用
Nvidia AI Enterprise 是一个全面的云原生软件平台,旨在加速数据科学流程,并简化生产级 Copilots 和其他生成式 AI 应用的开发与部署。
Nvidia NIM 在这个平台中扮演着重要角色,提供了一套易用的推理微服务,方便开发者能够在任何云或数据中心安全地部署基础模型。
Nvidia AI Enterprise 平台主要特点
- 丰富的框架和工具支持:提供 100+ 框架、预训练模型、开发工具和微服务,加速企业迈向 AI 前沿,简化 AI 应用开发。
- 多样化 AI 应用支持:涵盖生成式 AI、计算机视觉、语音 AI 等应用领域。
- 灵活的部署选择:可部署在 Nvidia DGX、Nvidia 合作伙伴认证的硬件和主流公有云(如 AWS、Azure 和 GCP)上。
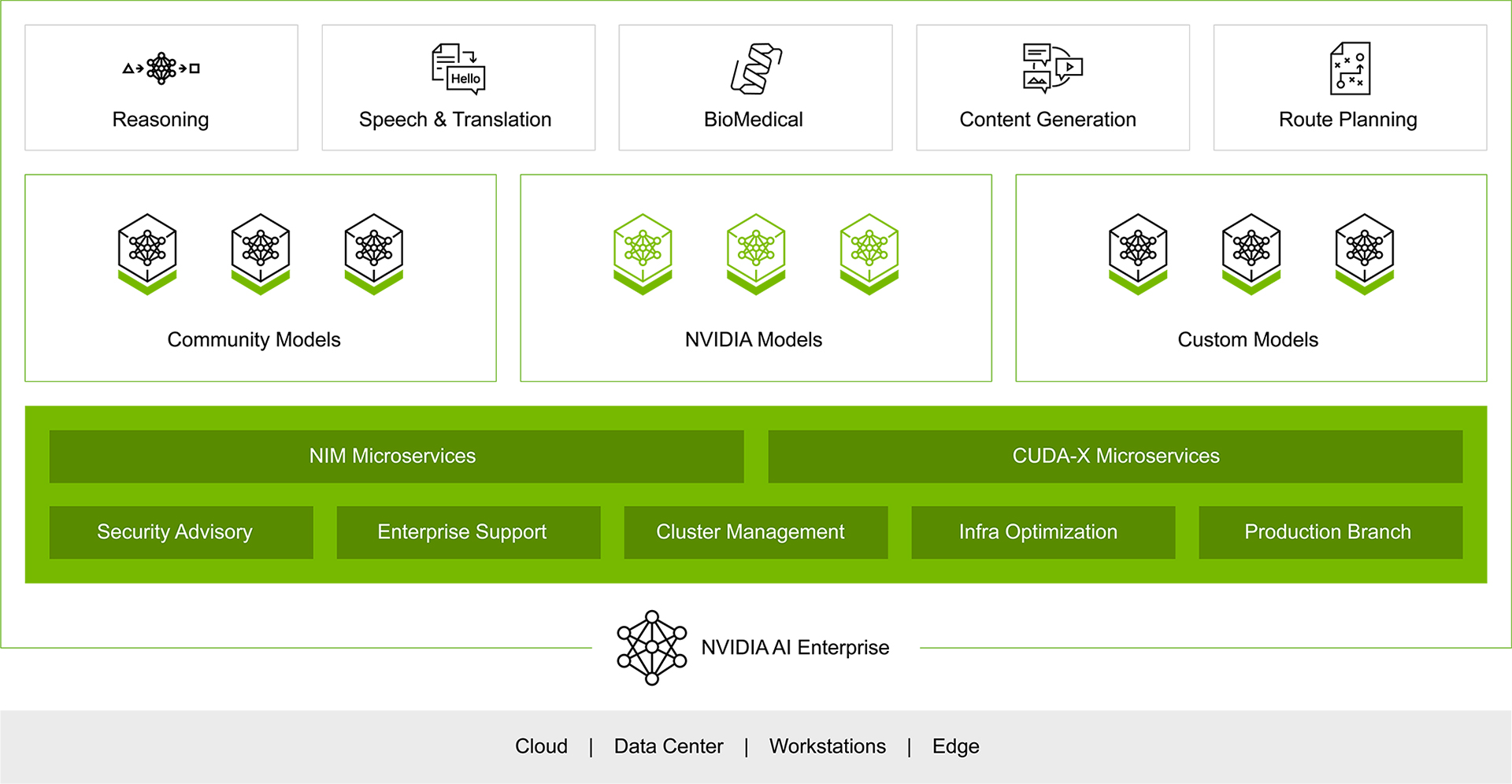
Nvidia NIM 作为 Nvidia AI Enterprise 平台的核心组件,提供了企业级的安全性、支持和稳定性,并优化了模型性能。开发者只需几行代码即可轻松部署 AI 模型,将复杂的 AI 模型部署交给 Nvidia 处理,专注于构建企业应用。
Nvidia NIM 自托管容器
对于无法使用 Nvidia AI Enterprise 的开发者,NIM 还提供了自托管容器镜像,支持通过 Docker 或 Kubernetes 进行部署。
NIM 抽象了模型推理的内部细节,无论是与 TRT-LLM、vLLM 还是其他推理引擎配合使用,都能确保高效运行。
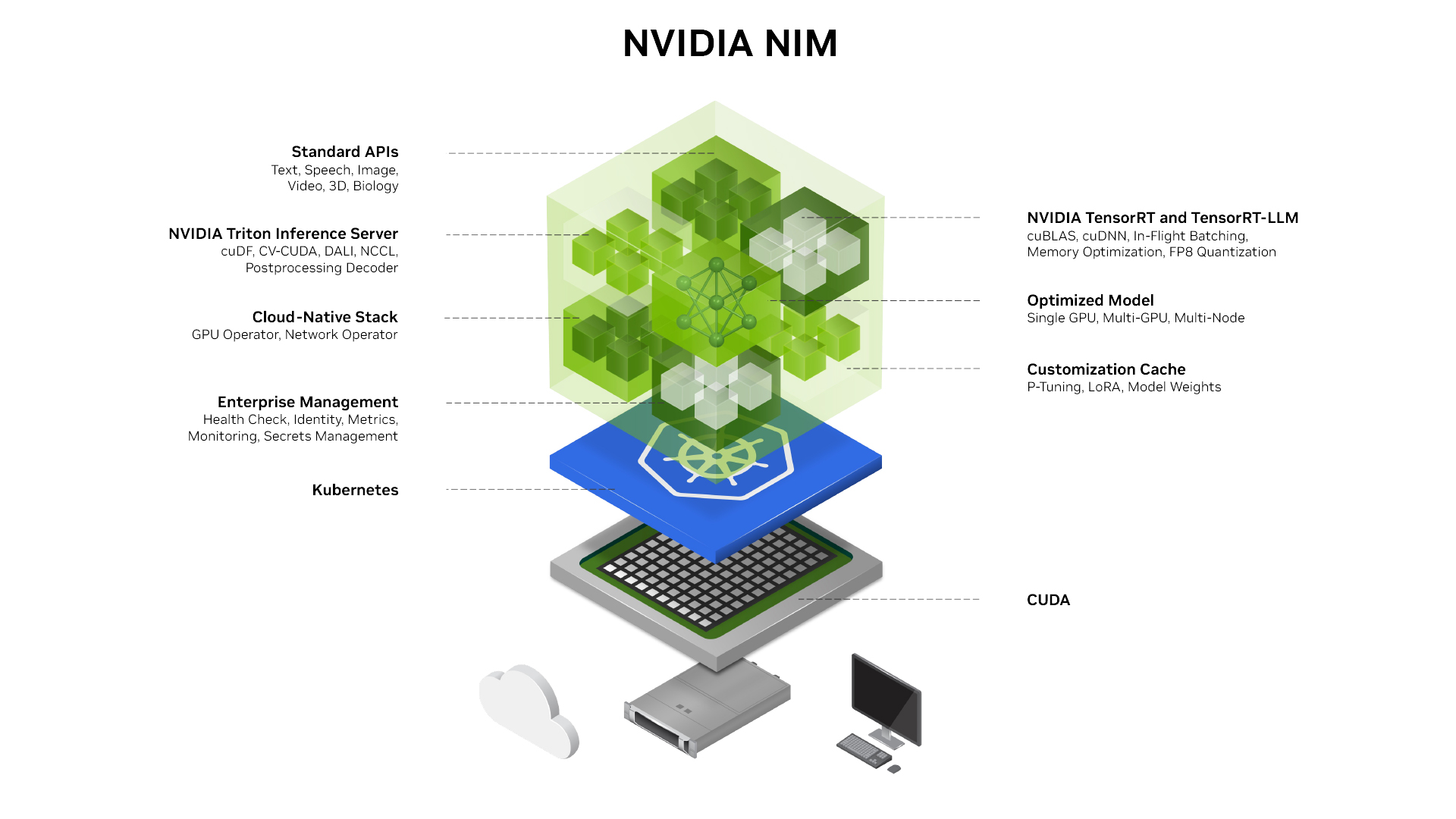
NIM 容器主要特点
- 容器化模型:以容器镜像形式提供模型或模型系列。
- 独立容器:每个 NIM 都是一个包含特定模型的 Docker 容器,例如
meta/llama3-8b-instruct。 - 自动下载和缓存:自动从 Nvidia 的 NGC 目录下载模型,并利用本地文件系统缓存。
- 一致性基础镜像:所有 NIM 都基于相同的基础镜像,下载额外 NIM 的速度非常快。
部署 Nvidia NIM 容器
NIM 容器可以在消费级 GPU(如 GeForce RTX 4090)上运行,让你能够在成本相对实惠的硬件上快速创建应用原型。
具体部署方法请参考官方 NVIDIA NIM for LLMs 入门指南。
首次部署 NIM 容器时,系统会检查本地硬件配置和模型注册表中的可用优化模型,并自动选择最适合当前硬件的版本。
- 对于支持的 GPU,NIM 会下载优化的 TensorRT (TRT) 引擎并使用 TRT-LLM 库进行推理。
- 对于其他 GPU,NIM 则会下载未优化的模型,并使用 vLLM 库运行。
总的来说,Nvidia NIM 提供了强大的工具和灵活的部署选项,让生成式 AI 模型的开发和应用变得更加高效和便捷。无论你是初学者还是资深开发者,NIM 都能轻松应对 AI 推理的复杂挑战,加速创新与落地。


最新评论
niubi
不知名软件:怪我咯!😏
在Win11下,第一次安装完后不要急着用,建议先重启一下。(我直接用的时候打开虚拟机报错了,重启后就正常了)
自动维护还是很重要的,我的就被不知名软件关闭了,导致系统时间落后正常时间15秒。用优化软件的一定要注意。