
为了探索实现人工智能所需的最小要素,微软训练并开源了 Phi-3 模型家族。这是微软目前最强大、最具成本效益的小型语言模型 (Small Language Model, SLM)。
与大型语言模型 (LLM) 相比,SLM 的参数量更少。例如,Phi-3-mini 只有 3.8B 参数,但其性能可以与拥有 45B 参数的 Mixtral 模型相媲美。这种小型但高效的模型可以在手机和网络边缘节点等设备上运行,为 AI 应用开辟了新的可能性。
Phi-3 模型家族
Phi-3 模型家族目前包含四个成员。每个模型都经过了指令调优,并严格遵循微软的负责任 AI 开发、安全和保密标准,用户无需额外调整即可直接使用:
- Phi-3-vision:这是一个拥有 4.2B 参数的多模态模型,具备语言理解和图像识别的双重能力。
- Phi-3-mini:是一个拥有 3.8B 参数的语言模型,提供了 128K 和 4K Token 两种上下文长度。
- Phi-3-small:是一个拥有 7B 参数的语言模型,提供了 128K 和 8K Token 两种上下文长度。
- Phi-3-medium:是一个拥有 14B 参数的语言模型,提供了 128K 和 4K Token 两种上下文长度。
Phi-3 的训练方法
正如《小而强大:蕴含巨大潜力的 Phi-3 小型语言模型》一文所述,这些模型都经过高质量数据的精心训练。并采用了创新的训练方法:
- 两阶段预训练:
- 第一阶段:使用经过严格筛选的网络数据,教授模型基础语言知识。
- 第二阶段:主要使用合成数据,教授模型更高级的概念。
- 合成数据的重要性:
- 针对特定概念精心设计提示,而不是简单地使用 LLM 生成大量文本
- 使用现实世界的种子数据,确保生成的内容有现实基础。
- 严格验证生成数据的质量和正确性。
- 数据质量与模型规模的关系:
- 强调数据质量的重要性,不同规模的模型需要不同类型的高质量数据。
- 通过精心设计的数据,可以使小型模型达到与大型模型相当的性能。
这种训练方法可以在保持模型小型化的同时,实现强大的推理能力。
Phi-3 的性能表现
在各种语言理解、逻辑推理、代码编写和数学运算的基准测试中,Phi-3 模型不仅超越了同等规模的模型,甚至表现要优于更大规模的模型。
Phi-3在关键基准测试上,要显著优于同等大小和更大尺寸的语言模型。其中,Phi-3-mini 的表现优于其两倍大小的模型,而 Phi-3-small 和 Phi-3-medium 则优于包括 GPT-3.5 Turbo 在内的更大模型。
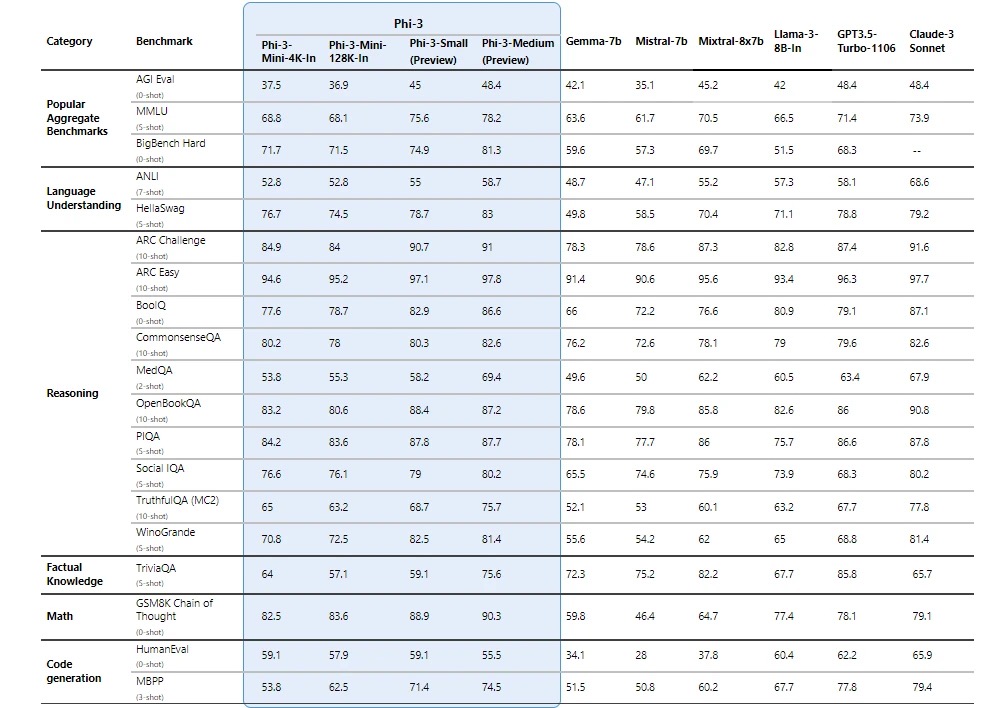
微软在技术论文中提供了更多关于基准测试的详细信息。
- Phi-3-mini 已经针对 ONNX Runtime 进行了优化,支持 Windows DirectML,能在 GPU、CPU 甚至移动设备硬件上提供跨平台支持。
- Phi-3 模型具有标准 API 接口,可以作为 NVIDIA NIM 推理微服务,并已针对 NVIDIA GPU 和 Intel 加速器进行了推理优化。
Phi-3 的应用场景
不同任务对模型规模的需求也各不相同,像 Phi-3 这样的小型语言模型特别适合以下场景:
- 资源受限环境:包括设备本地运行和离线推理场景。例如在飞机上提供离线 AI 助手服务,或需要本地处理以保护隐私的场景。
- 大规模调用场景:包括需要进行数百万次决策的应用,如智能路由系统和对延迟要求高的应用。例如在搜索引擎中进行查询分类和路由。
- 成本受限场景:包括成本敏感的应用,尤其是那些任务相对简单的场景。例如在客户支持系统中进行问题初步分类。
获取和使用 Phi-3
- 你可在 Hugging Face、Ollama 和 Azure AI Studio 的模型目录中获取和使用 Phi-3。
- 在 Azure AI 的模型即服务 (MaaS) 中,按需付费来调用 Phi-3 API。
Phi-3 作为一个小型但功能强大的语言模型,向我们展示了 AI 领域的新方向。通过创新的训练方法和高质量数据,Phi-3 实现了与大型模型相当的性能,同时保持了小型化和高效性。这为 AI 的广泛应用开辟了新的可能性,特别是在资源受限、成本受限或需要大规模部署的场景中。

最新评论
niubi
不知名软件:怪我咯!😏
在Win11下,第一次安装完后不要急着用,建议先重启一下。(我直接用的时候打开虚拟机报错了,重启后就正常了)
自动维护还是很重要的,我的就被不知名软件关闭了,导致系统时间落后正常时间15秒。用优化软件的一定要注意。