
grep 命令全名 global regular expression print(全局正则表达式打印),是 Linux 系统中最强大和最常用的命令之一。grep 可以搜索一个或多个(输入)文件,以查找与「给定模式」相匹配的行,并将每个匹配行写入标准输出。如果没有指定文件,grep 也可以将其它命令的输出作为标准输入进行读取。
下面系统极客就为大家介绍如何在 Linux 系统中使用 grep 命令进行搜索。
grep 命令语法
在讨论如何使用 grep 命令之前,让我们先回顾一下基本语法:
grep [OPTIONS] PATTERN [FILE...]
方括号中的项目是可选的。
- OPTIONS 提供 grep 控制其行为的 0 个或多个选项
- PATTERN 搜索模式
- FILE 0 个或多个输入文件(名)
使用 grep 在文件中搜索字符串
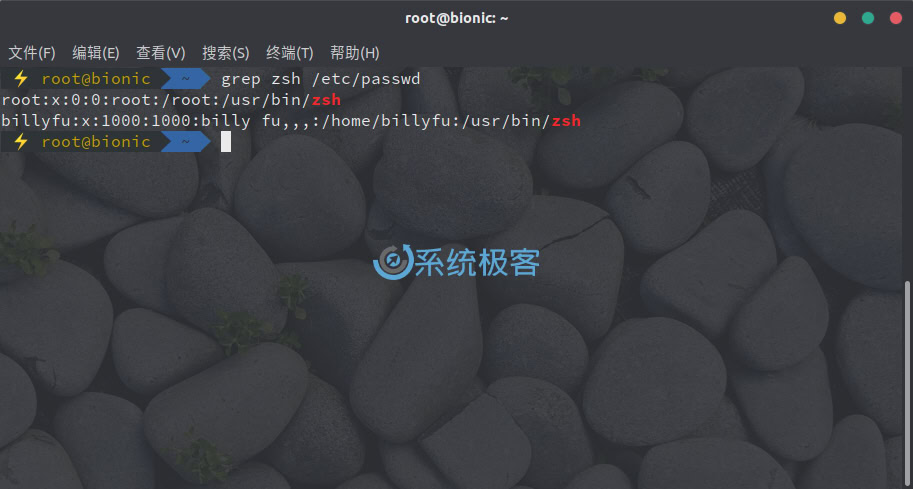
grep 命令最基本的用法就是在文件中搜索字符串(文本),例如要查看 /etc/passwd 文件中包含 zsh 的行,可以使用如下命令:
grep zsh /etc/passwd
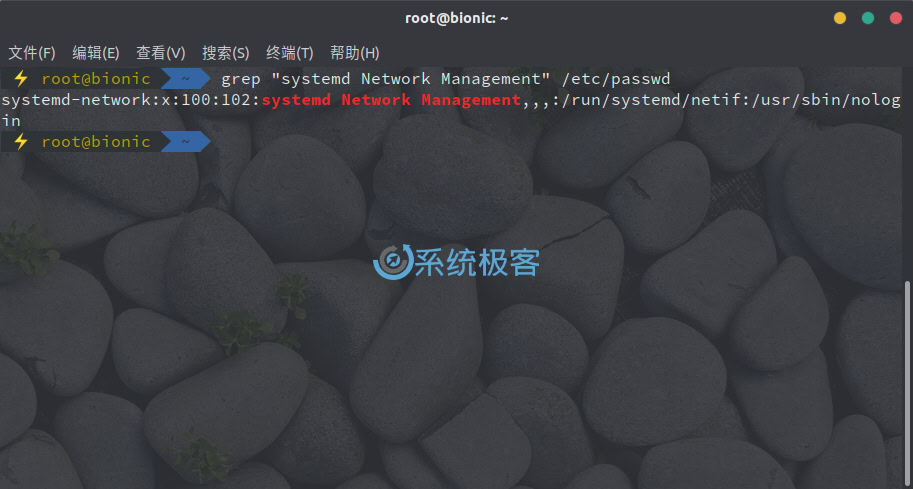
如果要搜索的字符串包含空格,则需要将其用单引号或双引号括起来,例如:
grep "systemd Network Management" /etc/passwd
grep 反向匹配(排除)
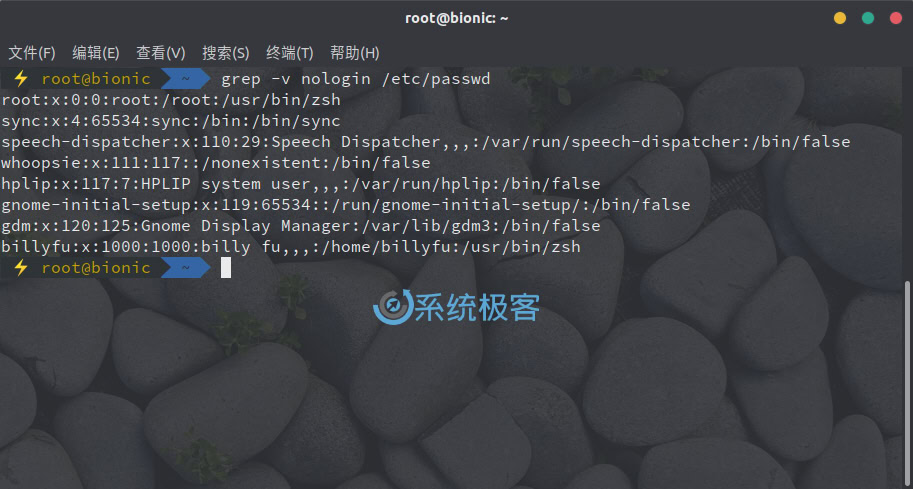
如果要显示与搜索模式不匹配的行,可以使用 -v 或 –invert-match 参数。例如,要查看 /etc/passwd 文件中不包含 nologin 的行,可以使用以下命令:
grep -v nologin /etc/passwd
grep 搜索另一命令的输出
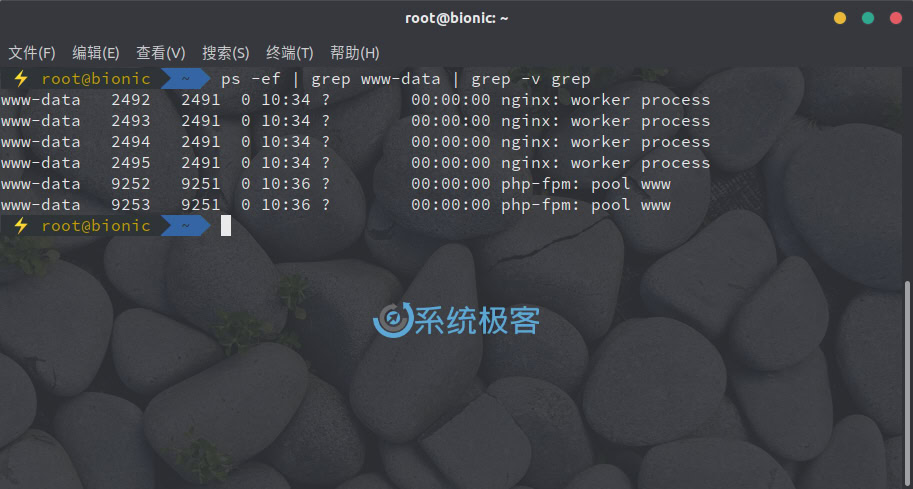
如果不是搜索文件,也可以将其它命令的输出结果传递给 grep 作为其搜索的「输入」。例如,要查找当前 Linux 中以 www-data 用户运行的进程,可以执行如下命令:
ps -ef | grep www-data
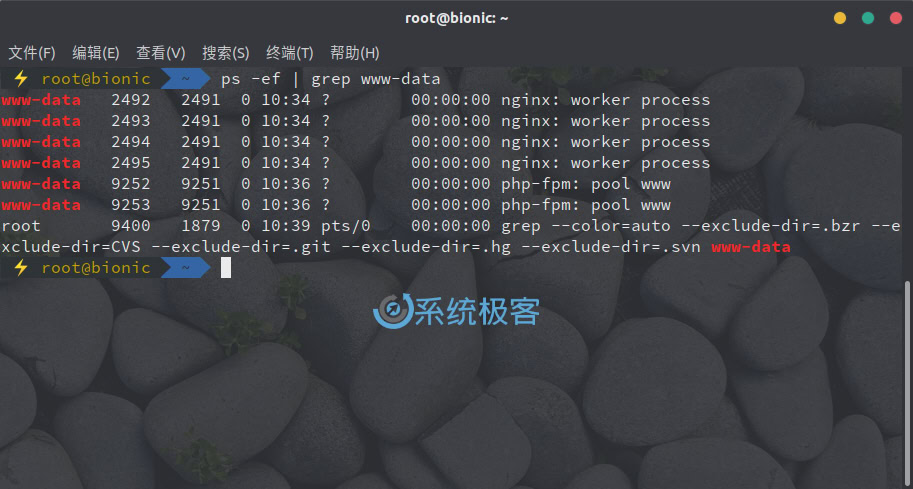
您还可以在命令中链接多个管道。从上图的输出中可以看到,有一行还包含了 grep 进程,如果不想显示该行,则可以将输出再次传递给另一个 grep 实例,例如:
grep 递归搜索
要使用递归搜索模式,请加上 -r 或 –recursive 参数,加上此参数后会搜索指定目录中的所有文件,遇到「符号链接」时会跳过。如果要搜索「符号链接」,需使用 -R 或 –dereference-recursive 参数。
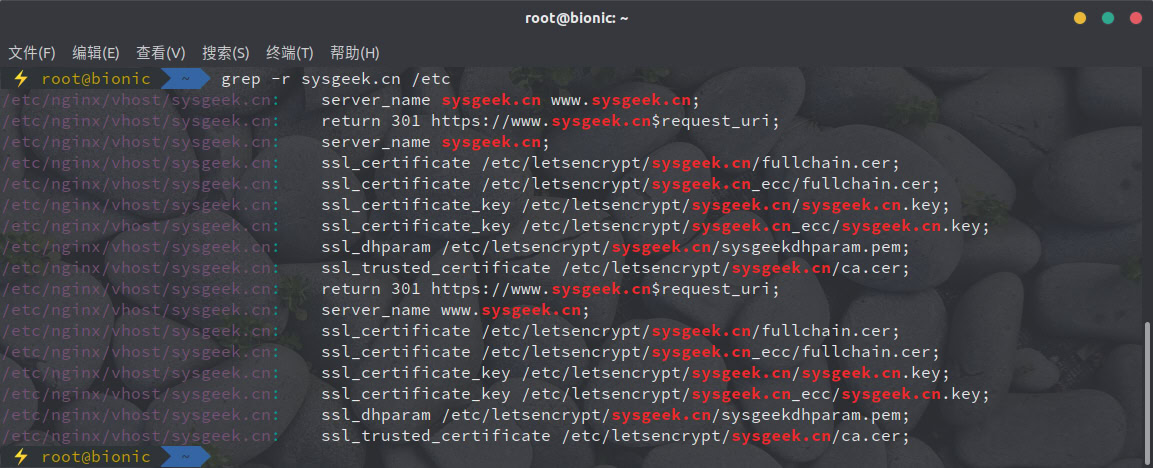
在下面的示例中,我们会递归搜索 /etc 目录中所有包含 sysgeek.cn 的字符串:
grep -r sysgeek.cn /etc
该命令将输出包含字符串的行,并在前面显示其文件名。
仅查看文件名
要禁止 grep 的默认输出,并仅显示包含「匹配模式」的文件名,可以使用 -l 或 –files-with-matches 参数。例如,要搜索当前目录中所有以 .conf 结尾并包含 sysgeek.cn字符串的文件,可以执行:
grep -l sysgeek.cn *.conf
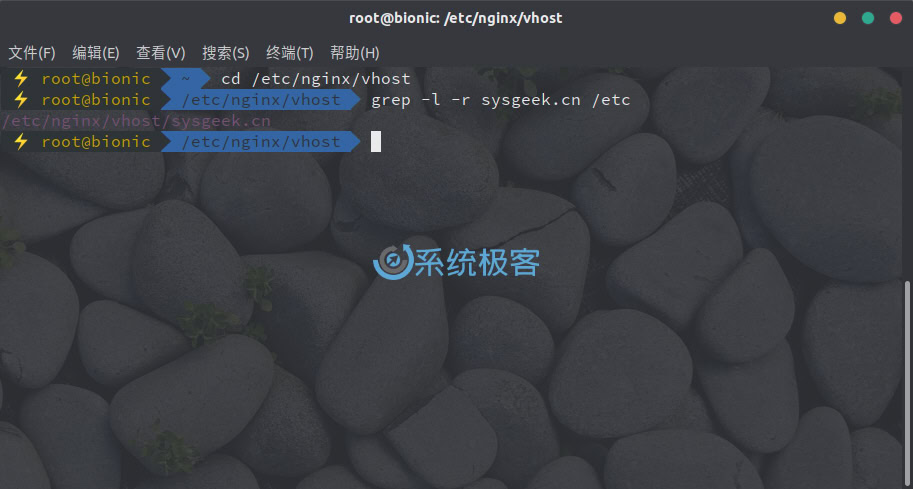
-l 参数通常会与递归参数 -R 结合使用,例如:
grep -Rl sysgeek.cn /tmp
配置 grep 不区分大小写
默认情况下,grep 是区分大小写的,也就是说大写和小写字符被视为不同。若要在搜索时忽略大小写,可以使用 -i 或 –ignore-case 参数。
grep 完全匹配
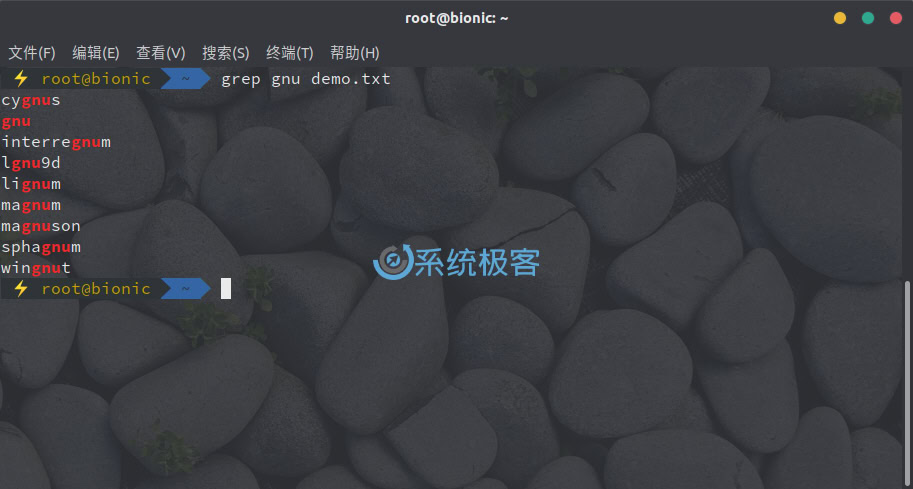
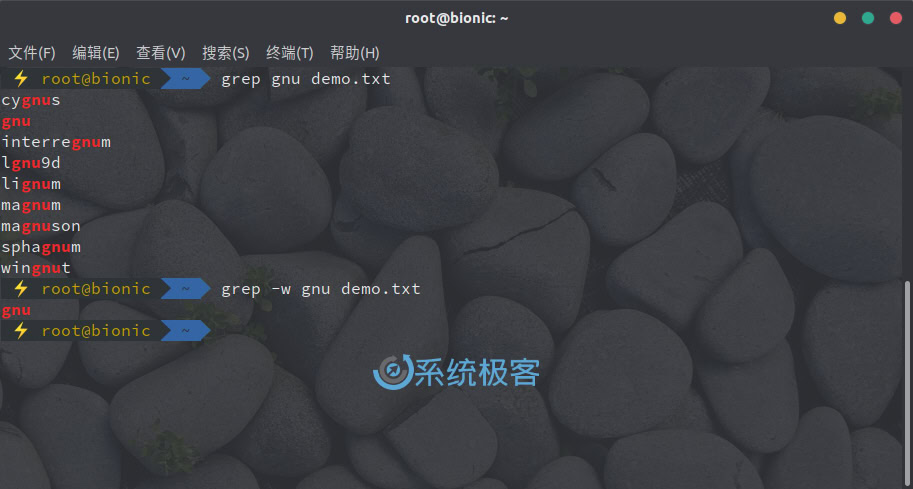
当用 grep 搜索 gnu 时,会自动匹配整个单词,如 cygnus 或 magnum:
grep gnu demo.txt
如果要完全匹配搜索的单词字符,可以加上 -w 或 –word-regexp 参数。
单词字符包括:字母、数字(a-z、A-Z 和 0-9)和下划线(_)。 其它所有字符都被视为非单词字符。
如果加上 -w 参数执行上述 grep 命令,则仅返回 gnu 作为单独单词的那些行:
grep -w gnu demo.txt
配置 grep 显示行号
要显示搜索字符串所在文本的行数时,可以使用 -n 或 –line-number 参数,加上该参数后,grep 会将匹配内容打印到标准输出,并添加所在文本行号为前缀。
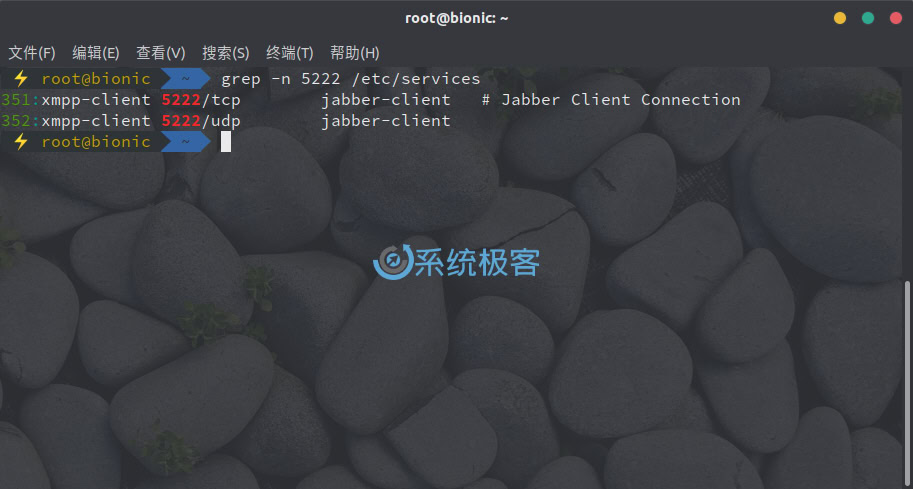
例如要查看 /etc/services 文件中 5222的所在行数,可以执行:
grep -n 5222 /etc/services
可以看到有 351 和 352 这两行:
使用 grep 计数
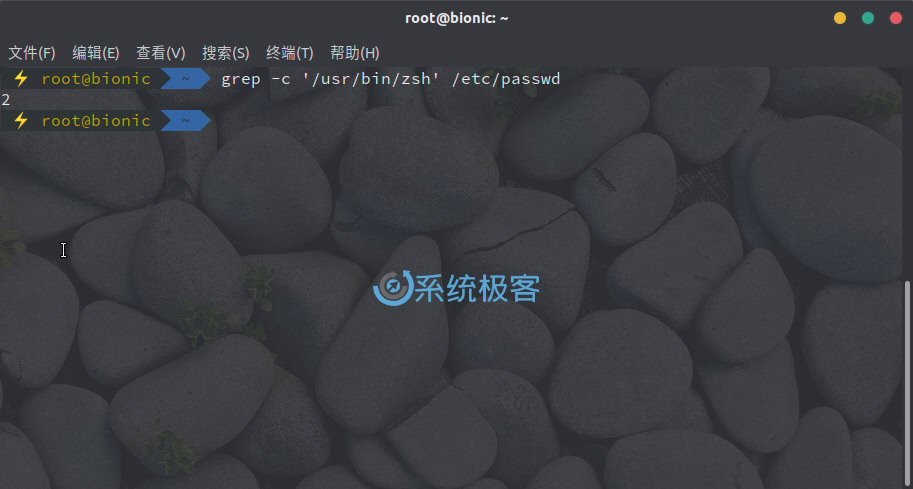
若要对匹配的行进行计数,可以使用 -c 或 –count 参数,例如要查看当前 Linux 中使用 ZSH 的账户数,可以使用如下命令:
grep -c '/usr/bin/zsh' /etc/passwd
grep 多个字符串(模式)
OR 运算符 | 可以连接两个或多个搜索模式。但默认情况下,grep 会将「模式」解释为基本正则表达式,其中「元字符」如 | 会失去其特殊意义,所以必需取反。
如下面的示例中,我们可以在 nginx 错误日志文件中搜索所有 fatal、error 和 critical 单词:
grep 'fatal\|error\|critical' /var/log/nginx/error.loge>
但如果加上扩展正则表达式参数 -E 或 –extended-regexp 参数,则运算符 | 不应取反,如下所示:
grep -E 'fatal|error|critical' /var/log/nginx/error.log
grep 正则表达式
grep 有「基本」和「扩展」两个正则表达式功能集,默认情况下,grep 的模式解释为基本正则表达式,要切换到扩展正则表达式需要加上 -E 参数。
当在「基本」模式下工作时,除「元字符」外的所有其他字符,都与原本的正则表达式相匹配。以下是最常用的「元字符」列表:
- ^(插入符号)用于匹配开头,例如 ^kangaroo 会匹配以其开头的行:
grep "^kangaroo" demo.txt
- $(美元符号)用于匹配行尾巴,使用 kangaroo$ 仅在其出现在一行的最后才匹配:
grep "kangaroo$" demo.txt
- .(句点)用以匹配任意单个字符,例如要匹配以 kan开头,中间有 2 个字符,然后以 roo结尾可以使用以下模式:
grep "kan..roo" demo.txt
- [](中括号)用以匹配中括号里的任意单个字符,例如要匹配 accept 或 accent,可以使用以下模式:
grep "acce[np]t" demo.txt
要屏蔽字符的特殊含义,请使用 \ 反斜杠。
grep 扩展正则表达式
扩展正则表达式包括所有基本元字符,以及其他扩展元字符,用以创建更复杂和强大的搜索模式。例如:
- 匹配并提取给定文件中的所有电子邮件地址:
grep -E -o "\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,6}\b" demo.txt
- 匹配并提取给定文件中的所有 IP 地址:
grep -E -o '(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)' demo.txt
-o 参数用于仅打印匹配的字符串。
打印 grep 匹配行的后 N 行
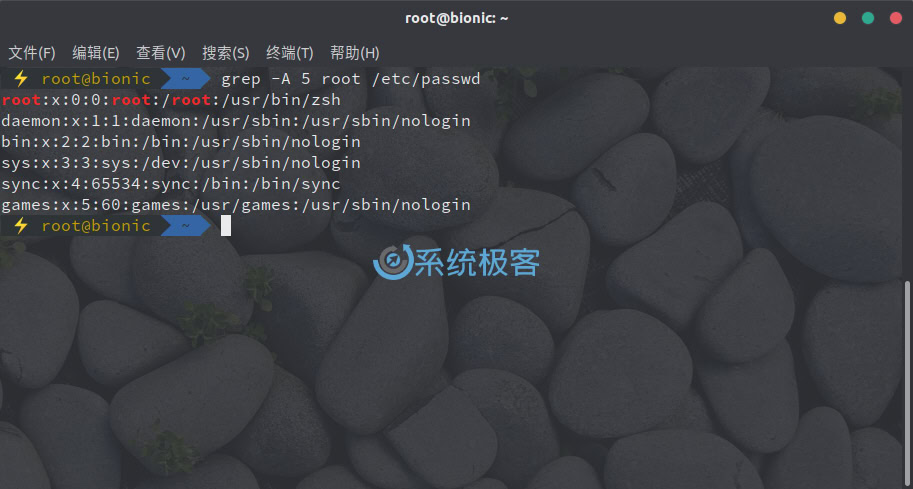
要打印匹配行后 N 行,请使用 -A 或 –after-context 参数。例如要显示匹配行和后 5 行,可以使用以下命令:
grep -A 5 root /etc/passwd
打印 grep 匹配行的前 N 行
要打印匹配行前 N 行,请使用 -B 或 –before-context 参数。例如要显示匹配行和前 3 行,可以使用以下命令:
grep -B 3 www-data /etc/passwd
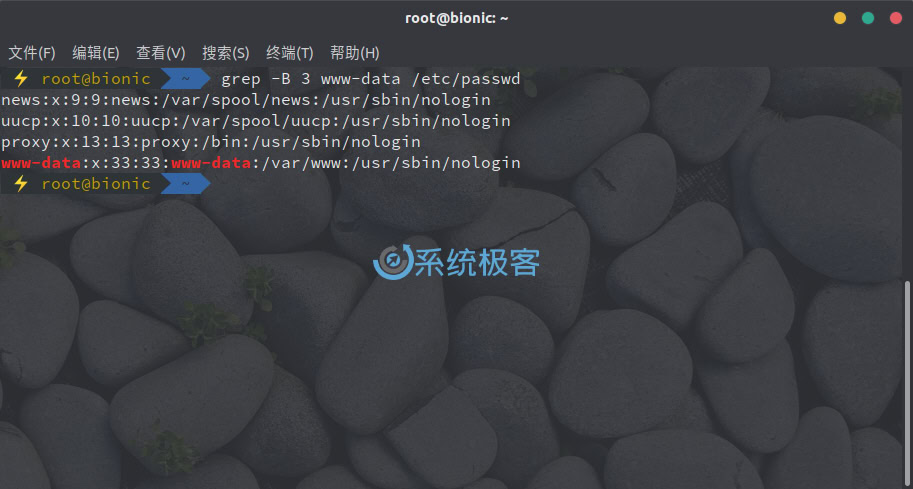
如果您想了解更多信息,可以参考 grep 用户手册。

几日不见网站终于可以访问了。哈哈。其实可以grep -100可以查看到匹配的前后100行内容