
自从 Google 对 Gemini 进行了品牌重塑之后,对 Gemini 的开发投入了大量工作,推出了基于 Gemini 1.0 Ultra 模型的高级版——Gemini Advanced。
虽然 Gemini Pro 这个核心模型已经在 Bard 平台上运行了一段时间,但 Google 没有满足于现状,还在继续推陈出新。最新的 Gemini 1.5 版本刚刚亮相,将会更新到免费版的 Pro 模型中。这次升级做了大量架构优化,让 Gemini 1.5 的性能有望与 Ultra 1.0 版本相匹敌。
Gemini 1.5 Pro:一次质的飞跃
在多个核心领域甚至超越了 GPT-4 Turbo
上下文理解能力大幅提升
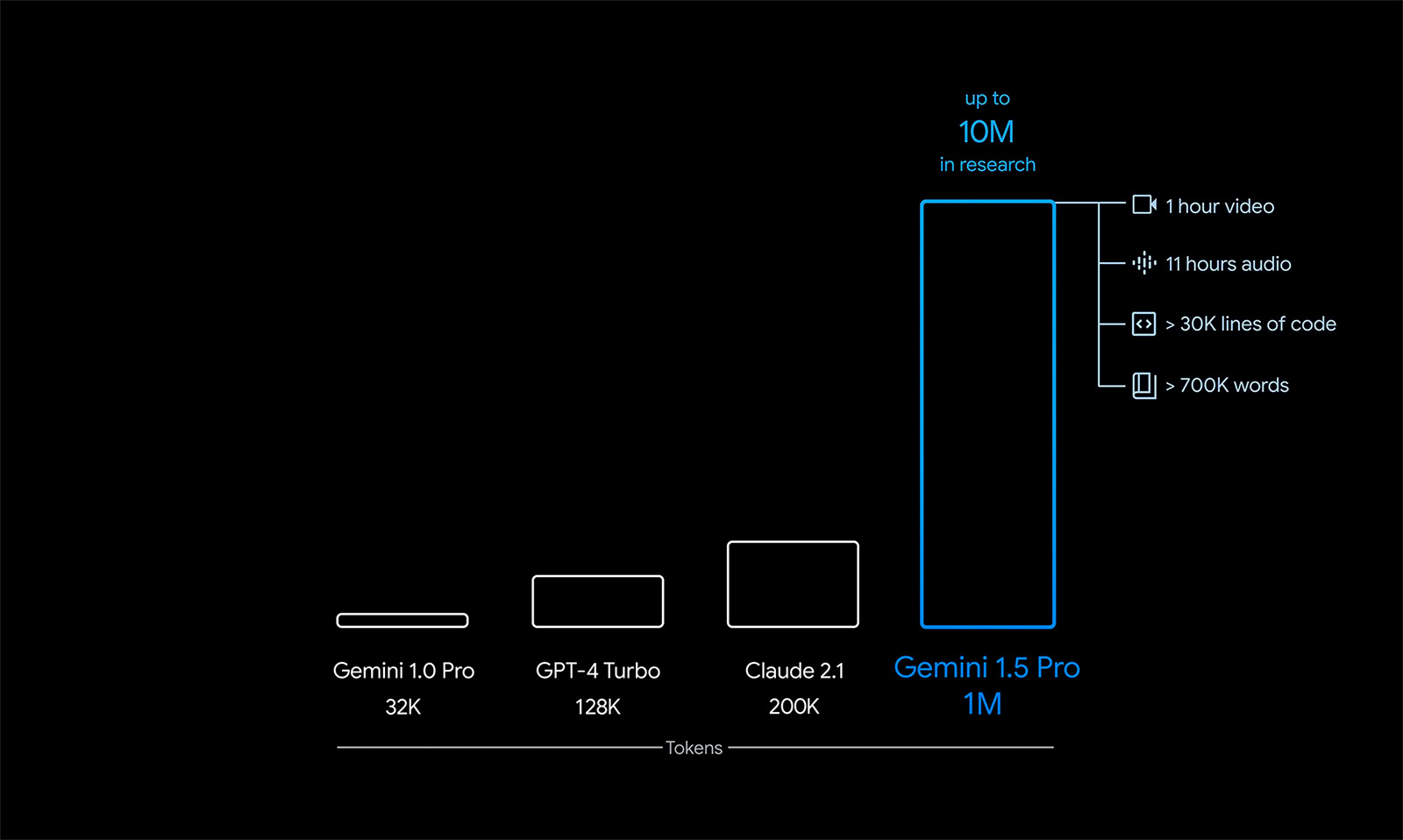
Gemini 1.5 Pro 在上下文信息处理能力上迎来了巨大突破,数据处理量从 32K Token 暴增到了 100 万 Token。简单来说,就是一次能够处理和分析的信息量大大增加了。相比之下,GPT-4 Turbo 的上下文理解能力只有 128K Token,而 Gemini 1.5 Pro 在特定的研究场景中,能够达到惊人的 1000 万 Token。
上下文理解能力的大幅提升,意味着模型能够一次性处理和理解更多的信息。比如,Google 展示了 Gemini 1.5 Pro 如何轻松处理阿波罗 11 号的全部航天通信记录,这份记录长达 402 页,但它能轻松回答出与这份记录相关的问题。
引入了混合专家模型(MoE)
Gemini 1.5 Pro 引入了混合专家模型(MoE)架构,此技术在 Mixtral 8x7B 模型中已经得到应用和验证。
MoE 架构通过将输入数据分配给系统中具有不同功能的神经网络来进行处理,从而实现了高度的专业化和定制化。
在 Mixtral 8x7B 模型中:
- 共有八组专家网络,每组都是针对特定任务的专家。这些专家网络不仅可以并行工作,还可以形成层级结构,其中某些专家网络本身也可能是 MoE 架构。
- 当处理输入时,Mixtral 8x7B 会利用一个决策网络来选择最合适的专家网络,每个数据单元都会由两个专家网络来分析,最终输出的结果也是这两个专家网络综合的答案。
MoE 方法的计算效率非常之高,特别是在模型的初期训练阶段。但它也可能在模型微调时导致过拟合问题。这意味着模型可能会变得对训练数据过于敏感,以至于在给出回答时会过分模仿训练数据,而不是根据输入灵活生成回答。
此外,MoE 模型还能够加快处理速度,因为只需针对每个查询激活部分专家网络。但是,为了支持如 Mixtral 这样的大型模型——其参数量高达 470 亿,需要配备相当大的内存。值得注意的是,模型并没有简单地将每个专家网络的参数数量简单相乘,而是实现了一些参数共享,这也是为什么参数量不是 560 亿(7B X 8),而是 470 亿的原因。
虽然上述讨论集中在 Mixtral 模型如何使用 MoE 上,但同样的架构和优化也被应用于 Gemini 1.5 Pro。我们可以合理推测,Google 在应用 MoE 架构的同时,也会加入自己的创新。
目前,Google 尚未公布 Gemini 1.5 Pro 的具体参数规模,但可以预见的是,MoE 的应用将使这款模型在实际运行时更为高效。
推理和问题解决能力的提升
Gemini 更善于逻辑和理解
Gemini 1.5 Pro 在理解各种输入(比如图像、文本)时和逻辑推理上展现了突破性的进步。比如,它能在分析一部 44 分钟的无声电影时,准确捕捉到主要情节和关键事件。
但是,Gemini 的进步还不止于处理多种形式的输入。Google 还表示,哪怕是面对超过 10 万行的复杂代码,Gemini 也能依据用户的特定需求来修改代码、提出解决方案,或者做出适当的调整。
开发者优先体验 Gemini 1.5 Pro
Google AI Studio 或 Vertex AI 的开发者现在已经可以申请加入等待列表,率先体验 Gemini 1.5 Pro 的限量预览版:
- 在 87% 的性能基准测试中,新模型超越了其前代产品 Gemini 1.0 Pro,并且在性能上可以媲美高端版本的 Gemini 1.0 Ultra。
- 值得一提的是,Gemini 1.5 Pro 能够在与用户的对话中实时学习,无需进行额外的微调。
- 巨大上下文窗口能力也是其独到之处,让它能够处理以往大语言模型无法应对的复杂任务。
在向公众全面推出时,Google 计划提供从标准的 128K Token 到最高可扩展至 100 万 Token 的不同定价层级。早期测试者需要注意的是,更大的上下文窗口可能会带来更高的响应延迟,但在测试阶段,将不会产生任何费用。


最新评论
niubi
不知名软件:怪我咯!😏
在Win11下,第一次安装完后不要急着用,建议先重启一下。(我直接用的时候打开虚拟机报错了,重启后就正常了)
自动维护还是很重要的,我的就被不知名软件关闭了,导致系统时间落后正常时间15秒。用优化软件的一定要注意。