
自从 OpenAI 推出 o1 推理模型后,AI 领域的关注点就转移到了「测试时计算」(Test-Time Compute),也就是推理扩展。现在,大家都不再一味追求更大的模型,而是开始琢磨如何让模型在推理时多「思考」一会儿,以此来提升逻辑推理能力和智能表现。这已经成为了新的趋势。
最近,Google 推出了首款推理模型 Gemini 2.0 Flash Thinking,其核心理念与 ChatGPT o1 类似,都会在给出最终答案之前,重新审视自己的回答。通过深入分析各种可能性,来力求答案的准确性。这种推理扩展技术确实让不少小模型都表现得非常惊艳。
随着 Google 入局「测试时计算」,形势变得越发有趣。网友们的火爆测试和各种骚操作更是让 Gemini 2.0 Flash Thinking 火出了圈。为此,我们也来好好对比一下 Gemini 2.0 Flash Thinking 和 OpenAI 的 o1 及 o1-mini 模型。为了让对比更加全面,我还特意拉了国内采用了类似策略的 DeepSeek-R1-Lite-Preview 进来。
闲话少说,直接来看 Gemini 2.0 Flash Thinking、ChatGPT o1 和 DeepSeek R1 Lite 的硬核对决吧!
推理大比拼
草莓问题
咱们先用一个经典的「草莓问题」来热热身,看看 AI 模型数单词中字母「r」的能力。
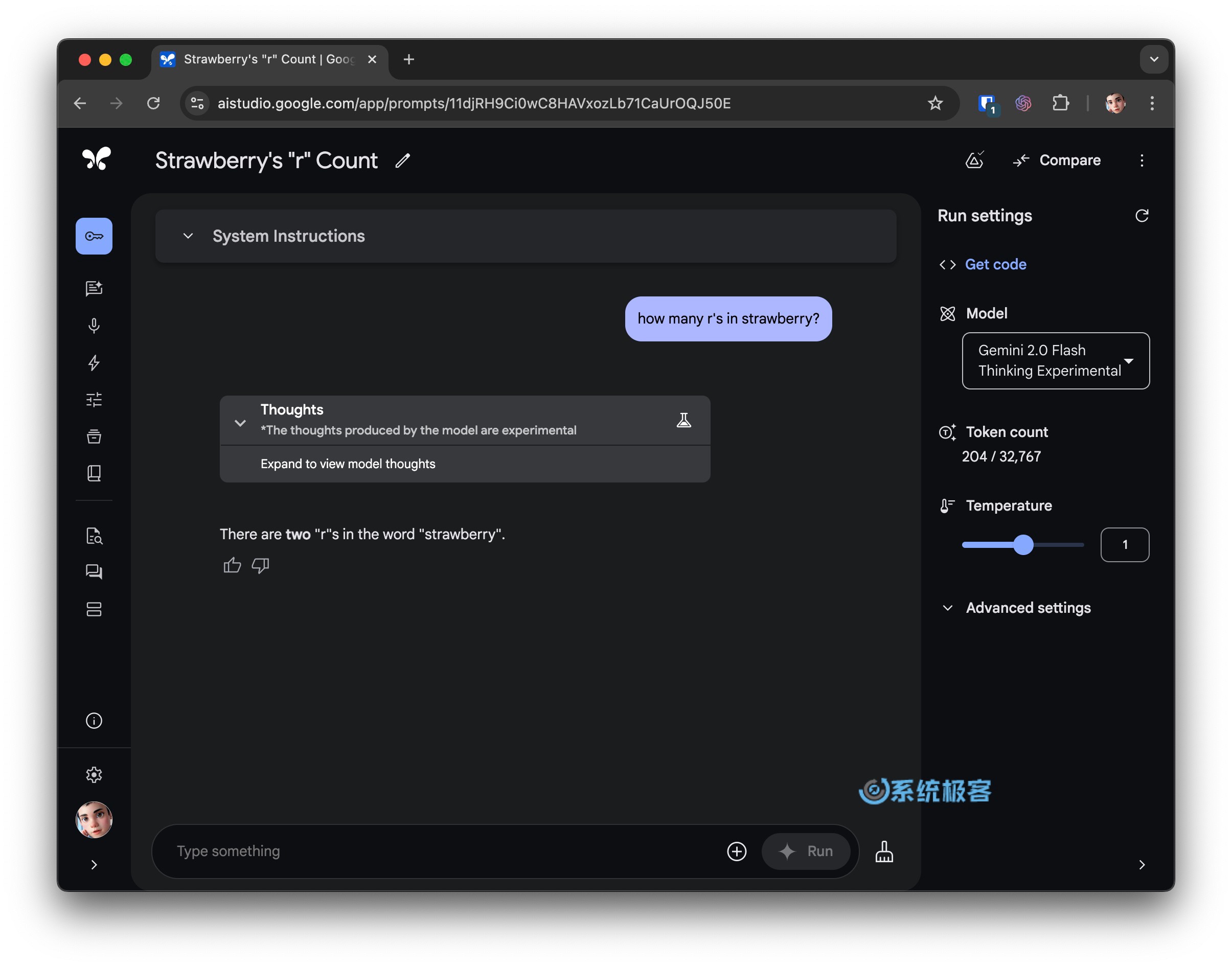
结果 Gemini 2.0 Flash Thinking 居然翻车了,它竟然认为单词「Strawberry」里只有两个「r」。而 ChatGPT o1 和 o1-mini 一次就答对了。DeepSeek R1 Lite 也毫不逊色,准确指出了有三个「r」。
加大难度
接下来,我加大了难度,让所有参赛模型列出名字里不带字母「a」的印度邦。
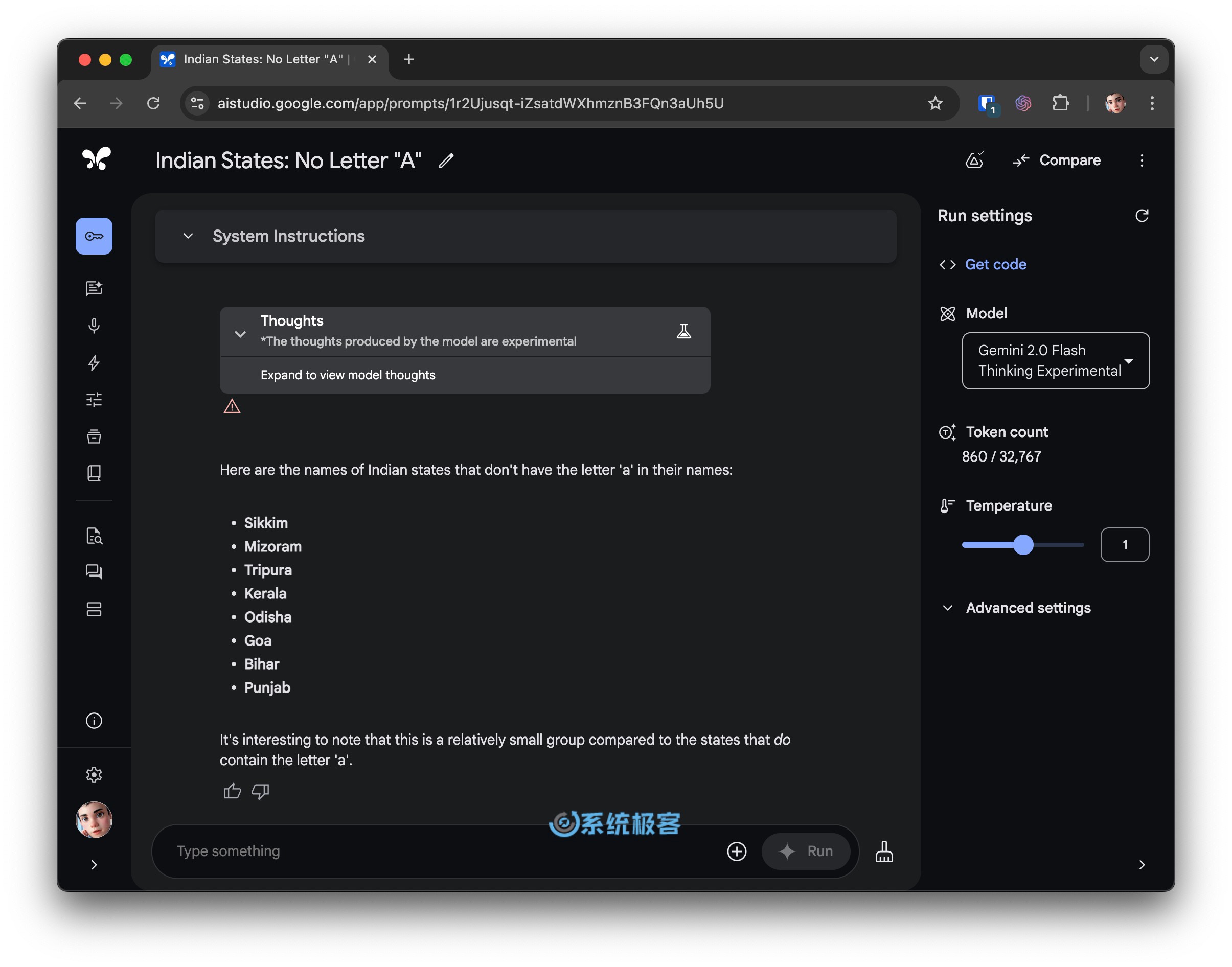
Gemini 2.0 Flash Thinking 虽然正确报出了 Sikkim(锡金),但却错误地画蛇添足,列了一堆带「a」的邦,这说明它在处理文字推理时还不太稳定。反观 ChatGPT o1、o1-mini 和 DeepSeek R1 Lite,依旧稳如老狗,精准指出只有锡金(Sikkim)符合要求。
烧脑问题
接着,我祭出了由 Riley Goodside 精心设计的烧脑问题,用来测试 AI 的联想和推理能力。题目如下:
Name a specific instance of the entertainment form whose acronym could also stand for the first names of a group who visited a country whose future leader married an Italian.
最终,只有 ChatGPT o1 准确答出了「Final Fantasy VII」,这是一款日式角色扮演游戏(JRPG)。提示中,披头士乐队的 John、Ringo、Paul 和 George 曾访问过印度,而印度的前总理拉吉夫·甘地 (Rajiv Gandhi) 娶了一位意大利人。
多模态能力
由于 Gemini 2.0 Flash Thinking 和 ChatGPT o1 都支持图片输入,我特意上传了一张出自 Gemini Cookbook 的一张数学题图片,求重叠区域面积。在这次多模态能力测试中,Gemini 2.0 Flash Thinking 可谓火力全开,表现优异,把 ChatGPT o1 比了下去。
What’s the area of the overlapping region?
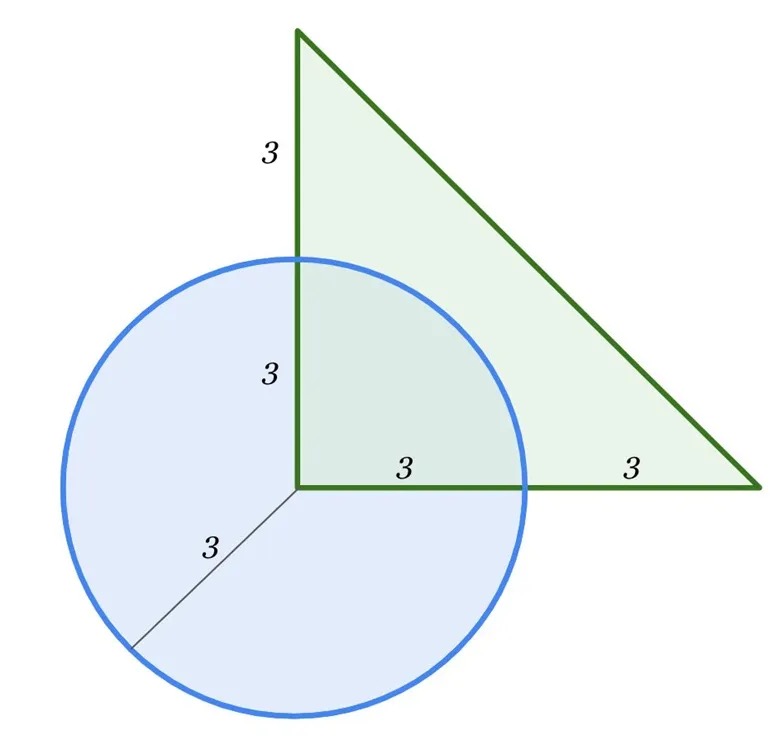
Gemini 2.0 Flash Thinking 不仅正确识别出三角形是直角三角形,还算出了重叠部分是圆的四分之一。接着,它用圆的面积除以 4,得到答案 9π/4。
反观 ChatGPT o1,它错误地将三角形识别成了等腰三角形,导致整个推理过程出现偏差。在处理多模态问题,特别是图像推理方面,Google 的技术优势已十分明显。
初步观感
Google 的 Gemini 2.0 Flash Thinking 模型确实给人一种更强更快的感觉,但从目前测试的初步印象来看,它的智商似乎还不如 ChatGPT o1,甚至略逊于小一号的 o1-mini。经过几轮测试,ChatGPT o1 的表现明显更细腻,且更注重事实依据。
当然,为了公平起见,我得补充一句,Gemini 2.0 Flash Thinking 模型是基于较小号的 Gemini 2.0 Flash 模型开发的,拿它和目前业界领头羊 ChatGPT o1 直接对比,确实有点不公平。我预计,等到出了更高性能的 Gemini 2.0 Pro Thinking 模型后,其模型扩展能力会更强,推理性能也会更上层楼。
不过,Gemini 2.0 Flash Thinking 也有自己的绝活,它在多模态理解方面表现抢眼,视频、音频、图像处理样样精通,这让它在处理多模态任务时,比大多数竞争对手要强上一截。 还有些用户发现 Gemini 2.0 Flash Thinking 成功搞定了 Putnam 2024 问题和三个赌徒问题,这说明它的应用场景已经不局限于传统的推理任务了。
尽管如此,AI 在推理和智能领域的探索也才刚刚开始。我相信在 2025 年,我们会在推理能力方面看到质的飞跃,届时肯定会有更多惊喜等着我们!


最新评论
不知名软件:怪我咯!😏
在Win11下,第一次安装完后不要急着用,建议先重启一下。(我直接用的时候打开虚拟机报错了,重启后就正常了)
自动维护还是很重要的,我的就被不知名软件关闭了,导致系统时间落后正常时间15秒。用优化软件的一定要注意。
刷不到新版更新