Anthropic 正式发布了新版 Claude 3.5 Sonnet,并推出了全新的 Claude 3.5 Haiku 模型:
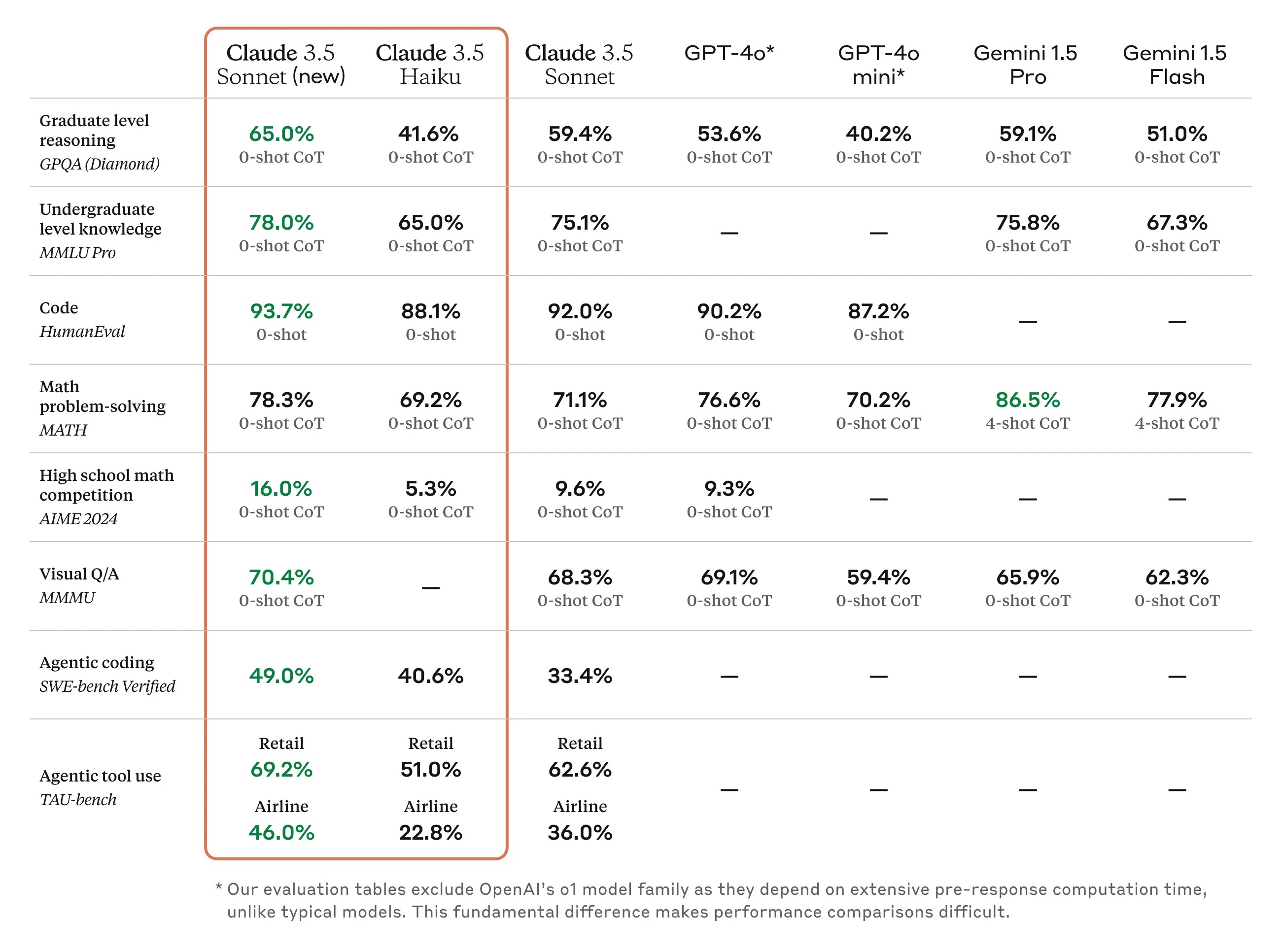
- 升级后的 Claude 3.5 Sonnet 在多个领域都有显著提升,尤其在它擅长的编程领域,又取得了突破性进展。
- 新发布的 Claude 3.5 Haiku 在多项测试中表现出色,能与 Claude 3 Opus 相媲美,同时还保持了与上一代 Haiku 相近的速度和成本优势。
革命性功能:计算机使用能力
Anthropic 还启动了全新的「计算机使用能力」(Computer Use) 公测。通过 Computer Use API,开发者可以教导 Claude 模拟人类操作计算机,包括观察屏幕、移动鼠标、点击按钮和输入文字。该功能能够自动化重复性工作,支持软件开发和测试,甚至用于开放式研究任务。
Claude 3.5 Sonnet 是首个支持「计算机使用能力」的 AI 模型,但该功能仍处于实验阶段,可能存在一定的局限和错误。
通过 Computer Use API,Claude 能够感知和交互计算机界面,将指令转化为计算机操作,例如:
- 使用本地或在线数据填写表格。
- 查看电子表格、打开浏览器并访问相关网页,用获取到的数据填充表单。
在 OSWorld 测试中,Claude 3.5 Sonnet 在「仅截图」类别中得分 14.9%,领先于其他 AI 系统;当允许更多操作步骤时,得分提升到了 22.0%。
Claude 3.5 Sonnet:软件工程能力的行业标杆
新版 Claude 3.5 Sonnet 在多项行业基准测试中取得了全面的进步,尤其是在智能体编码 (Agentic Coding) 和工具使用 (Tool Use) 任务中突破明显:
- 在编程领域,它在 SWE-bench Verified 测试中的得分从 33.4% 提升到了 49.0%,超越了所有公开可用的模型,包括 OpenAI o1-preview 等推理模型和专门为智能体编码设计的系统。
- 在 TAU-bench 测试中,新版 Claude 3.5 Sonnet 在零售领域的得分从 62.6% 提升到了 69.2%;在航空领域从 36.0% 提升到了 46.0%。这一进步还是在价格和速度保持不变的情况下实现的。
- 新版 Claude 3.5 Sonnet 在发布前经过了美国 AI 安全研究所(US AISI)和英国安全研究所(UK AISI)的联合测试,确保了模型的可靠性和安全性。
升级版 Claude 3.5 Sonnet 现已对所有用户开放。开发者现在就可以通过 Anthropic API、Amazon Bedrock 和 Google Cloud 的 Vertex AI 平台使用这款支持「计算机使用能力」的测试版模型。
Claude 3.5 Haiku:性能与性价比的完美结合
Claude 3.5 Haiku 是 Anthropic 最新的快速模型。它保持了与 Claude 3 Haiku 相同成本和速度,并在各项能力上实现了显著提升,甚至超越了 Claude 3 Opus。
- 在编程任务中,Claude 3.5 Haiku 在 SWE-bench Verified 测试中的得分达到了 40.6%,超越了多款公开可用的顶尖 AI 模型,包括原版 Claude 3.5 Sonnet 和 GPT-4o。
- Claude 3.5 Haiku 凭借低延迟、出色的指令理解能力和更精准的工具使用能力,非常适合拿来开发用户产品、处理子智能体任务,或从海量数据(如购买记录、价格或库存信息)中生成个性化体验。
Claude 3.5 Haiku 预计将于本月晚些时候上线,初期仅支持文本输入功能,图像输入功能将在后续版本中推出,届时可通过 Anthropic API、Amazon Bedrock 和 Google Cloud 的 Vertex AI 平台使用。




最新评论
亲测24H2有效,谢谢
无法记录系统日志,影响故障排查和安全审计。依赖于 rsyslog 进行日志记录的应用和服务可能会遇到问题。
您好,想请问一下是关闭后有其他影响吗
肯定啊!